Распознавание текста, оцифровка книг
Копировальный центр Scanmasters предлагает услуги по распознаванию текста, оптимизации деловой и бухгалтерской документации. Услуга сканирования позволяет облегчить чтение информации и обеспечить удобный доступ к данным, оцифровать большое количество информации с целью сохранения и защиты.
Цены на распознавание текста
Перечень услуг
Стоимость услуг
Распознавание текста
Автоматическое распознавание
Распознавание c ручным определением зон(текст, таблицы, формулы)
Корректировка и проверка на соответствие(в т.ч. таблицы)
Сохранение в Microsoft Word/PDF
бесплатно!
Минимальная сумма заказа 100р *срочные заказы рассчитываются индивидуально в зависимости от нашей загрузки. Указанные цены не являются публичной офертой. Из-за постоянного изменения цен на расходные материалы, уточняйте актуальные цены у менеджера.



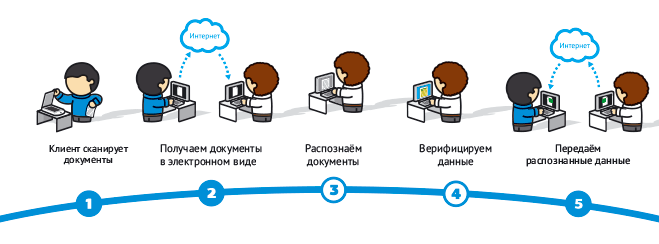
Распознавание книг
- оцифровка полученных данных (используются профессиональное ПО);
- верификация данных;
- передача информации клиенту или перенос на электронные носители.
Распознавание текста в нашем центре

Копировальный центр Scanmasters предоставляет следующие услуги:
- распознавание текста с бумажных носителей любого типа, включая книги;
- улучшение качества текста или изображения, обрезка;
- перевод данных в требуемый формат, редактирование и проверка данных, адаптация для доступа к информации на ПК, смартфоне и прочих гаджетах.
Для оформления заказа или получения дополнительной информации звоните нам по телефонам +7 (925) 789-37-87, +7 (925) 451-22-69
Автоматизация документооборота на SharePoint
Ни для кого не секрет, что средства поиска SharePoint являются мощным инструментом в повседневной деятельности каждой компании, использующей корпоративный портал от Microsoft. Так, при поиске учитываются словоформы и морфология, то есть не нужно заботиться о вводе точной фразы, потому что слова «портал» и «портале» система распознает как одно слово «портал». Результаты поиска будут ранжированы, поэтому поиск всегда будет релевантным, так как наиболее подходящие результаты будут первыми в списке.
Кроме того, в SharePoint реализована возможность полнотекстового поиска по текстовому содержимому электронных документов. Однако значительную часть документов в любой компании занимают отсканированные копии бумажных документов, не имеющие электронной текстовой версии.
Помещение таких документов в SharePoint включает в себя промежуточный этап сохранения электронной копии документа на компьютер пользователя, и найти такие документы по текстовому содержимому стандартными средствами не представляется возможным. Именно поэтому было принято решение разработать программное обеспечение Модуль сканирования и распознавания К-Док, которое расширяет базовую функциональность SharePoint, позволяя сканировать документ напрямую на портал и осуществлять поиск графического документа по его текстовому содержимому.
Возможности решения
Модуль сканирования и распознавания К-Док способен производить распознавание текста графических файлов, находящихся в библиотеках документов SharePoint. При этом пользователь имеет возможность в настройках библиотеки управлять механизмом распознавания текста, то есть указывать следует ли распознавать текст в файлах данной библиотеки, или нет, как показано на рисунке 1.
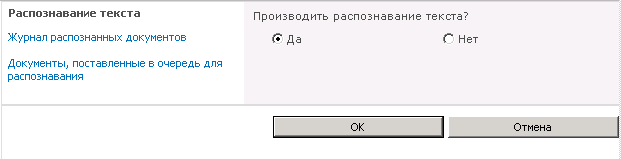
Рисунок 1. Управление механизмом распознавания текста
Кроме того, предусмотрена функция распознавания текста документа в индивидуальном порядке, она представлена на рисунке 2.
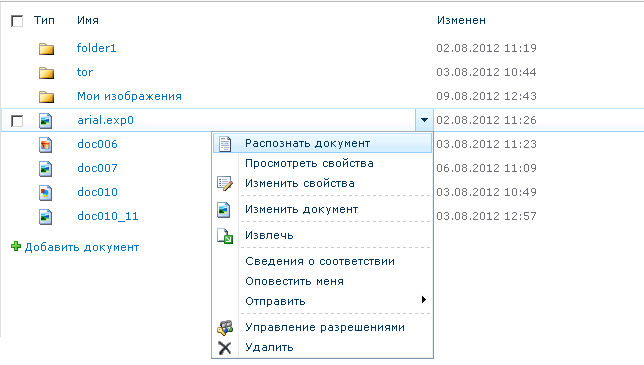
Рисунок 2. Распознавание текста документа в индивидуальном порядке
Для контроля над работой Модуля сканирования и распознавания К-Док предназначен журнал распознавания текста, в котором отображаются текущие состояния документов, поставленных в очередь на распознавание – рисунок 3.
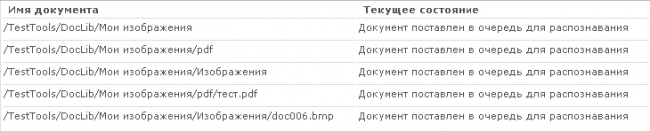
Рисунок 3. Очередь документов для распознавания
На рисунке 4 представлена уже обработанная очередь документов, где пользователю предоставлена информация о результатах распознавания.
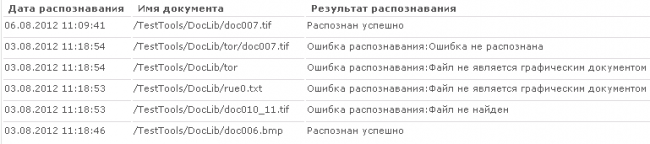
Рисунок 4. Журнал распознанных документов
Так по графическому документу Страница Трудового кодекса.tif в результате распознавания был получен текст. Сам файл предварительно был помещен в библиотеку документов SharePoint. На рисунке 5 показано, что исходный документ удалось найти по его текстовому содержимому, используя стандартные средства SharePoint, где в качестве ключевого слова поиска была указана фраза «Цели и задачи законодательства».
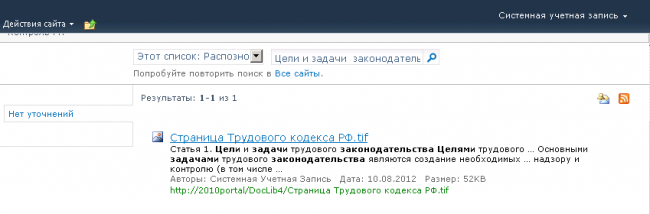
Рисунок 5. Результаты поиска
Пользователь, используя браузер, способен сканировать бумажные документы и сохранять их электронные копии в библиотеку SharePoint, при этом операция сканирования совмещена с операцией выгрузки документа на портал. Кроме того, сохраняемое изображение конвертируется в формат PDF с текстовым слоем, который получается в результате оптического распознавания текста.
На рисунке 6 представлено приложение Модуль сканирования К-Док, которое реализует функции сканирования и помещения документов на портал. Программное обеспечение не требует ручной установки на компьютер пользователя, система предложит установить необходимые компоненты при первом использовании.

Рисунок 6. Модуль сканирования К-Док
Приложение поддерживает такие возможности сканеров как двустороннее сканирование и автоматическая подача оригиналов. Эти функции чрезвычайно полезны, т. к. в купе с возможностью сохранения нескольких изображений в один документ позволяют автоматизировать процесс оцифровки архивов. Для этого сотруднику достаточно положить в устройство стопку бумаги, и начать процесс сканирования, а по его завершению сохранить файл в библиотеку документов SharePoint.
Для тонкой настройки качества сканирования реализована возможность вызова меню используемого сканера, где пользователь может произвести специфическую настройку, не предусмотренную интерфейсом программы.
Характеристики Модуля сканирования и распознавания К-док
Поддерживаемые форматы
Модуль сканирования и распознавания К-Док способен работать со следующими графическими форматами: BMP, EMF, GIF, JPEG, PNG, TIFF (в т. ч. многостраничный).
Ведется работа над распознаванием текста в файлах формата PDF.
Распознавание текста
При оптическом распознавании приложение извлекает текст, игнорируя разметку. Программное обеспечение позволяет извлекать текст из двуязычных документов, в которых используются русские и английские символы. Качество распознавания сильно зависит от качества изображения, в идеальном случае точность распознавания превышает 95%.
Системные требования
- Microsoft Windows Server 2008 R2 SP1 или выше;
- Microsoft SharePoint Server 2013;
- Microsoft SQL Server 2008 R2 SP1 или выше.
- Internet Explorer 8 или выше, Mozilla Firefox и Google Chrome последних версий;
- .NET Framework 4.0.
Дистрибутив можно скачать по ссылке загрузки.
Надеемся, что предоставленный инструмент окажется Вам полезным.
Отчеты об ошибках и результатах использования, как и пожелания, пожалуйста, отправляйте по адресу support@sdcv.ru.
- Дистрибутив приложения (ссылка);
- Пример страницы для распознавания (ссылка);
- Результат распознавания страницы из п.3 (ссылка);
- .NET Framework 4.0 (http://www.microsoft.com/en-us/download/details.aspx?id=17718).
Свежие записи
- Выпущено решение для бизнес анализа «СДЦ. Портал бизнес-аналитики»
- Компания СДЦ завершила разработку Digital Workplace — цифрового рабочего места.
- Выполнен перенос решения «СДЦ. Типовой портал» на последние версии Microsoft SharePoint
- Компания СДЦ — поставщик облачных решений Microsoft (CSP)
- Доработан модуль сканирования и распознавания
Системы распознавания текста
Программы и системы распознавания текста (СРТ, англ. Text Recognition Systems, TRS) предназначены для сканирования текстовых данных, обработки графических данных и извлечения полезной информации из документов различных видов. С помощью данных программных продуктов часто, обрабатываются счета-фактуры, акты, накладные, квитанции, клиентские формы, опросные листы и документы сотрудников.
Читать далее
Сравнение Системы распознавания текста
Выбрать по критериям:
Подходит для
Специалист
Малый бизнес
Средний бизнес
Корпорация
Администрирование
Импорт/экспорт данных
Многопользовательский доступ
Наличие API
Отчётность и аналитика
Тарификация
Ежемесячная оплата
Ежегодная оплата
Единовременная оплата
Оплата потребления
По запросу
Развёртывание
Сервер предприятия
Мобильное устройство
Персональный компьютер
Облако (SaaS)
Графический интерфейс
Веб-браузер
Поддержка языков
Азербайджанский
Белорусский
Бенгальский
Болгарский
Венгерский
Вьетнамский
Грузинский
Индонезийский
Итальянский
Каталонский
Латвийский
Монгольский
Нидерландский
Норвежский
Персидский
Португальский
Украинский
Французский
Хорватский
Английский
Сортировать: по алфавиту по полноте сведений
Tesseract OCR от Google
Tesseract – это программный движок с открытым исходным кодом, позволяющий распознавать символы с поддержкой кодировки Unicode и возможностью распознавания более 130 языков, а также с возможностью дополнения для распознавания других языков. Узнать больше про Tesseract OCR
ABBYY FineReader от ABBYY
ABBYY FineReader – это универсальное программное приложение для распознавания текста, предназначенное для повышения производительности бизнеса, быстрого захвата документов на бумажных носителях и получения на выходе оцифрованных файлв в форматах PDF, DOC и прочих. Узнать больше про ABBYY FineReader
Yandex Vision от Яндекс.Облако
Yandex Vision – это онлайн-сервис визуальной аналитики, позволяющий реализовывать распознавание текста и объектов на изображениях с помощью программных моделей машинного обучения. Сервис используется на базе программного интерфейса (API). Узнать больше про Yandex Vision
Руководство по покупке Системы распознавания текста
1. Что такое Системы распознавания текста
Программы и системы распознавания текста (СРТ, англ. Text Recognition Systems, TRS) предназначены для сканирования текстовых данных, обработки графических данных и извлечения полезной информации из документов различных видов. С помощью данных программных продуктов часто, обрабатываются счета-фактуры, акты, накладные, квитанции, клиентские формы, опросные листы и документы сотрудников.
2. Обзор основных функций и возможностей Системы распознавания текста
Администрирование Возможность администрирования позволяет осуществлять настройку и управление функциональностью системы, а также управление учётными записями и правами доступа к системе. Импорт/экспорт данных Возможность импорта и/или экспорта данных в продукте позволяет загрузить данные из наиболее популярных файловых форматов или выгрузить рабочие данные в файл для дальнейшего использования в другом ПО. Многопользовательский доступ Возможность многопользовательской доступа в программную систему обеспечивает одновременную работу нескольких пользователей на одной базе данных под собственными учётными записями. Пользователи в этом случае могут иметь отличающиеся права доступа к данным и функциям программного обеспечения. Наличие API Часто при использовании современного делового программного обеспечения возникает потребность автоматической передачи данных из одного ПО в другое. Например, может быть полезно автоматически передавать данные из Системы управления взаимоотношениями с клиентами (CRM) в Систему бухгалтерского учёта (БУ). Для обеспечения такого и подобных сопряжений программные системы оснащаются специальными Прикладными программными интерфейсами (англ. API, Application Programming Interface). С помощью таких API любые компетентные программисты смогут связать два программных продукта между собой для автоматического обмена информацией. Отчётность и аналитика Наличие у продукта функций подготовки отчётности и/или аналитики позволяют получать систематизированные и визуализированные данные из системы для последующего анализа и принятия решений на основе данных.
Электронный считыватель текста для кого предназначен

PDF , то его придется перевести в растровый формат, минуя процесс сканирования. То же касается, если оригинал уже в виде файла в растровом формате. В этом случае процесс подготовки оригинала и процесс самого сканирование мы опускаем, при условии, что цифровой оригинал отвечает всем требованиям для успешного распознавания.
Итак, запустив программу распознавания и получив ее результат можно считать, что половина дела сделана. Почему только половина, спросите Вы? Все потому, что хотя прогресс и не стоит на месте, но многое еще не подвластно даже самому современному компьютеру и самой лучшей программе распознавания. И хотя процент корректного распознавания с хорошего оригинала стремится к 100%, но все же на последнем этапе в работу включается человек. Корректировать возможные ошибки распознавания придется вручную. Но тем не менее весь процесс распознавания и коррекции с сотни раз быстрее нежели ручной набор по оригиналу более менее солидного по объему документа. Современные средства распознавания «владеют» несколькими языками, сохраняют не только текст, но и фотографии, чертежи, сохраняя при этом верстку и формат документа. Оцифрованный и распознанный документ Вы вольны изменять и редактировать уже по своему усмотрению, конвертируя его в любой удобный для вас формат.
От чего же зависит успешное распознавание документа? Наверное, оцифровка документа и его последующее распознавание, тот редкий случай, когда копия по всем параметром будет лучше оригинала. Но для этого нужно выполнить несколько условий. Во-первых исходный материал, а именно оригинальный документ, должен быть максимально хорошего качества. Мятая, надорванная бумага, плохо пропечатанный или выгоревший текст, «хитрый» шрифт (а тем более рукописный) все это ведет к ухудшению результата распознавания. Во-вторых, сканер или другое устройство (в некоторых случаях используются специальные фотоаппараты) получения оптической копии должен выдавать результат с хорошим разрешением и (если требуется) цветопередачей. В третьих, программное и компьютерное обеспечение должно позволять получить максимально возможный процент распознавания документа. Не выполнение хотя бы одного из этих условий снижает процент распознавания в разы, а это значит, что больше времени потребуется для ручной корректировки документа.
Для чего же могут потребоваться оцифрованный и распознанные документы? Создание электронных архивов и библиотек, всевозможные картотеки и каталоги, базы данных, распространение электронных версий изданий и книг, публикация в интернете, продажа и обмен электронных версий документов и архивов. Оцифровка и распознавание древнейших библиотек дает нам доступ к огромному опыту человечества практически из любой точки планеты. Область применения цифровых технологий становится поистине безгранична.
Страница сгенерирована за 0.01 секунд !