Классифицируем ошибки из PostgreSQL-логов
В логах работающих систем рано или поздно появляются тексты каких-то ошибок. Чем таких систем больше в обозримом пространстве, тем больше вероятность ошибку увидеть. Серверы PostgreSQL, которые находятся под нашим мониторингом ежедневно генерируют от 300K до, в неудачный день, 12M записей об ошибках.
И такие ошибки — это не какой-то там «о, ужас!», а вполне нормальное поведение сложных алгоритмов с высокой степенью конкурентности вроде тех, о которых я рассказывал в статье про расчет себестоимости в СБИС — все эти deadlock, could not obtain lock on row in relation … , canceling statement due to lock timeout как следствие выставленных разработчиком statement/lock timeout.
Но есть ведь и другие виды ошибок — например, you don’t own a lock of type . , которая возникает при неправильном использовании рекомендательных блокировок и может очень быстро «закопать» ваш сервер, или, мало ли, кто-то периодически пытается «подобрать ключик» к нему, вызывая возникновение password authentication failed for user …

Собственно, это все нас подводит к мысли, что если мы не хотим потом хвататься за голову, то возникающие в логах PostgreSQL ошибки недостаточно просто «считать поштучно» — их надо аккуратно классифицировать. Но для этого нам придется решить нетривиальную задачу индексированного поиска регулярного выражения, наиболее подходящего для строки.
Понятно, что можно хранить оригинальный текст всех ошибок и как-то потом обобщать и группировать их «в динамике», но это не очень-то эффективно. Гораздо полезнее оставлять только ссылку на оригинальный формат, плюс аргументы из конкретной строки.
Поскольку разработчики PostgreSQL тоже достаточно разумные ребята, все вызовы форматирования строки ошибки сделаны через единую функцию errmsg .
На самом деле, это не совсем правда, и полный список выглядит чуть шире:
elog, errmsg, psql_error, gettext_noop, GUC_check_errmsg
Если мы будем иметь возможность разбора строки ошибки «по формату», то вместо текста сможем хранить лишь ID формата и переменную часть (если она присутствует). Очевидно, что это занимает меньше места, чем полная строка. Плюсом, мы получаем ту самую возможность группировки по формату.
Шаг №1: собираем форматы
Тут все просто — идем в официальный репозиторий PostgreSQL, качаем исходники, парсим, получаем форматы. Звучит просто, на деле же нам потребуется доступ к GitHub API (и чтобы им не злоупотреблять, мы постараемся соблюдать паузы 10ms между запросами, а вот распараллеливанием работы заниматься не будем) и немного RegExp-магии:
const util = require('util'); // npm install async github-api const async = require('async'); const GitHub = require('github-api'); // сюда будем складывать все промежуточные результаты let scheduler = < 'path' : [] , 'file' : [] , 'msgs' : [] >; // timestamp последнего запроса let tsReq; // потребуются ваши user/pass на github let gh = new GitHub(< username : 'foo' , password : 'bar' >); // подключаемся к репозиторию let repo = gh.getRepo('postgres/postgres'); async.series([ cb => < // заносим в очередь пути до всех релизных веток и master repo.listBranches((err, res) => < if (err) < console.log(util.inspect(err)); >else < // можно не качать все-все версии, а ограничиться только теми, которые у вас реально присутствуют scheduler.path = [ . res.map(obj =>obj.name).filter(name => name.endsWith('_STABLE')) , 'master' ].map(name => name + ':'); > return cb(err); >); > , cb => < // сканируем всю структуру веток "в глубину", отбирая файлы *.c/*.l async.whilst( cb =>cb(null, scheduler.path.length) , cb => < let _path = scheduler.path.shift(); console.log('now scanned : ' + _path); let [ref, path] = _path.split(':'); tsReq = Date.now(); repo.getContents(ref, path, false, (err, res) => < if (err) < console.log(util.inspect(err)); scheduler.path.unshift(_path); setTimeout(() =>cb(), 1000); // sleep return; > else < scheduler.path = scheduler.path.concat( res .filter(item =>item.type == 'dir') .map(item => ref + ':' + item.path) ); scheduler.file = scheduler.file.concat( res .filter(item => item.type == 'file' && /\.(c|l)$/.test(item.path)) // .c | .l .map(item => ref + ':' + item.path) ); let lag = Date.now() - tsReq; setTimeout(() => cb(), lag >= 10 ? 0 : 10 - lag); // API rate > >); > , (err, n) => cb(err) ); > , cb => < // выкачиваем содержимое всех найденных файлов и вырезаем форматные строки const RE_ERR = ['elog', 'errmsg', 'psql_error', 'gettext_noop', 'GUC_check_errmsg'] .map(func =>'(?:\\W)' + func + '\\((?:\\w+,|)[\\s\\n]*"(.*?[^\\\\])"((?:\\s*\\n\\s*"(.*?[^\\\\])")*)[,\\)]') .map(re => (< g : RegExp(re, 'gm') , l : RegExp(re) >)); const RE_SPC = RegExp('\\s*\\n\\s*"(.*?[^\\\\])"', 'g'); scheduler.file.sort(); async.whilst( cb => cb(null, scheduler.file.length) , cb => < let _path = scheduler.file.shift(); console.log('now parsed : ' + _path); let [ref, path] = _path.split(':'); tsReq = Date.now(); repo.getContents(ref, path, false, (err, res) => < if (err) < console.log(util.inspect(err)); scheduler.file.unshift(_path); setTimeout(() =>cb(), 1000); // sleep return; > else < let str = Buffer.from(res.content, 'base64').toString(); let errs = RE_ERR.reduce((rv, re) =>rv.concat( (str.match(re.g) || []) .map(s => < re.l.exec(s); let re1 = RegExp.$1 , re2 = RegExp.$2; if (re2) < re2 = re2.replace(RE_SPC, '$1'); >return (re1 + (re2 ? re2 : '')).replace(/\\"/g, '"'); >) ), []); let msgs = [. new Set(errs)]; // избавляемся от дублей if (msgs.length) < console.log(msgs); scheduler.msgs.push(msgs); >let lag = Date.now() - tsReq; setTimeout(() => cb(), lag >= 10 ? 0 : 10 - lag); // API rate > >); > , (err, n) => cb(err) ); > , cb => < // готовим в errmsg.sql итоговый запрос для вставки, уникализируя форматы let sql = ['INSERT INTO dicerrmsg(message) VALUES\n ']; sql.push( [. new Set(scheduler.msgs.reduce((rv, arr) =>rv.concat(arr), []))] .map(msg => "(E'" + msg.replace(/'/g, "''") + "')") .join('\n, ') ); sql.push('\n;\n'); require('fs').writeFileSync('errmsg.sql', sql.join('')); return cb(null); > ]); На данный момент со всех версий получается чуть больше 14K форматов.
Шаг №2: словарь форматов
Маленькая неприятность — форматы описаны в терминах printf-подстановок. То есть получаем что-то вроде:
syntax error at or near «%s»
cursor «%s» does not exist
block number %u is out of range for relation «%s»
could not parse value «%s» for parameter «%s«
С такими форматами работать не очень удобно, поэтому приведем каждый из них в вид, который нам поможет быстро определять формат по строке и отображать подстановки переменных:
CREATE TABLE dicerrmsg( errmsg serial PRIMARY KEY , message -- оригинальный формат varchar UNIQUE , regexp -- проверяющее регулярное выражение varchar , template -- шаблон для подстановки аргументов varchar , prefix -- префикс до первой подстановки varchar ); -- индекс для префиксного поиска префиксов :) CREATE INDEX ON dicerrmsg(prefix varchar_pattern_ops); Должно получиться что-то типа этого:

В этом нам поможет триггер на вставку в таблицу:
CREATE OR REPLACE FUNCTION errins() RETURNS trigger AS $$ BEGIN -- защита от повторной перезаливки через COPY PERFORM NULL FROM dicerrmsg WHERE message = NEW.message LIMIT 1; IF FOUND THEN RETURN NULL; END IF; -- рекурсивно находим и подменяем все printf-подстановки на regexp-формат -- http://www.cplusplus.com/reference/cstdio/printf/ WITH RECURSIVE rpl AS ( SELECT row_number() OVER() rn , * FROM ( VALUES ('%%', E'\1%\1') , ('%d', E'(-?\\d+)') , ('%02d', E'(-?\\d)') , ('%3d', E'(-?\\d)') , ('%03d', E'(-?\\d)') , ('%ld', E'(-?\\d+)') , ('%i', E'(-?\\d+)') , ('%u', E'(\\d+)') , ('%lu', E'(\\d+)') , ('%zu', E'(\\d+)') , ('%o', E'([0-7]+)') , ('%x', E'([0-9a-f]+)') , ('%2x', E'([0-9a-f])') , ('%02x', E'([0-9a-f])') , ('%X', E'([0-9A-F]+)') , ('%02X', E'([0-9A-F])') , ('%08X', E'([0-9A-F])') , ('%f', E'(-?\\d+(?:\\.\\d+)?)') , ('%\\.0f', E'(-?\\d+)') , ('%\\.1f', E'(-?\\d+\\.\\d)') , ('%\\.2f', E'(-?\\d+\\.\\d)') , ('%\\.3f', E'(-?\\d+\\.\\d)') , ('%e', E'(-?\\d+(?:\\.\\d+)?e[-+]\\d+)') , ('%02g', E'(-?\\d)') , ('%g', E'(-?\\d+(?:\\.\\d+)?|-?\\d+(?:\\.\\d+)?e[-+]\\d+)') , ('%c', E'(.*)') , ('%s', E'(.*)') , ('%\\.32s', E'(.)') , ('%\\.*s', E'(.*)') , ('%p', E'([0-9a-f])') , ('%m', E'(.*)') ) T(token, re) ) , T AS ( SELECT 0 lvl , '^' || regexp_replace( regexp_replace( regexp_replace( regexp_replace( NEW.message , '\r' , '\\r' , 'g' ) , '\n' , '\\n' , 'g' ) , '\t' , '\\t' , 'g' ) , '([\(\)\[\]\\^\$\.\+\-\?\|\\])' , '\\\1' , 'ig' ) || '$' str , NEW.message tmp UNION ALL SELECT T.lvl + 1 lvl , regexp_replace(str, rpl.token, rpl.re, 'g') str , regexp_replace(tmp, rpl.token, E'\1', 'g') tmp FROM T JOIN rpl ON T.lvl + 1 = rpl.rn ) -- формируем regexp, шаблон отображения и префикс по итогу последней подстановки SELECT regexp_replace(str, E'\1%\1', '%', 'g') str , regexp_replace(tmp, E'\1%\1', '%', 'g') tmp , regexp_replace( regexp_replace(tmp, E'\1%\1', '%', 'g') , E'\1.*$' , '' ) prf INTO NEW.regexp , NEW.template , NEW.prefix FROM T ORDER BY lvl DESC LIMIT 1; -- RETURN NEW; END; $$ LANGUAGE plpgsql; CREATE TRIGGER ins BEFORE INSERT ON dicerrmsg FOR EACH ROW EXECUTE PROCEDURE errins();Внимательный взгляд уже заметил на предыдущей картинке, что в таблице у нас помимо оригинального формата и regexp лежат еще два поля: разбитая на сегменты строка и константный префикс. Строку мы используем в интерфейсе для красивого отображения, а вот с префиксом все интереснее…
Префикс — это тот «фиксированный» текст, который должен присутствовать в начале строки, чтобы она могла быть отнесена к данному формату. То есть текст формата до позиции первой подстановки:
Берем формат: block number %u is out of range for relation «%s»
Получаем: block number
Шаг №3: разбор ошибки по форматам
В большинстве случаев формат определяется, но бывают и «неформатные» ошибки — например, результат явно сгенерированного разработчиком RAISE ERROR . Для таких мы держим в базе отдельное поле с полным текстом — обычно там NULL, поэтому практически ничего не «стоит» для хранения. Если же мы определили формат — сохраняем его ID и массив подставляемых параметров:
CREATE TABLE err( -- . , errpos -- позиция ошибки, если в тексте есть ". at position 123" integer , errmsg -- ID формата integer , errargs -- массив параметров text[] , error -- почти всегда пустой "неформатный" текст varchar );Заранее мы не знаем, присутствует ли вообще в строке с ошибкой какая-то подстановка и где она начинается, если все-таки она там есть. И если индексный поиск строк по regexp существует в pg_trgm еще с версии 9.3, то для обратной задачи поиска наиболее подходящего regexp для строки алгоритм придется реализовать нам самим.
Какие вообще возможны варианты при разборе строки по набору форматов?
Совпадающие префиксы
Префикс какого-то формата полностью совпал с нашей строкой ошибки. Тогда нам надо всего лишь убедиться, что наша строка подходит под полный regexp. И из подходящих выбрать формат наибольшей длины (чтобы у нас не выбирался постоянно формат «%s», например).
«Мы делили апельсин. »
Если же с префиксом совпадает только часть строки, то тут сложнее, ведь мы вообще не знаем, где в нашей входной строке кончается префикс и начинается подставленный параметр.
Ну что ж… Префикс неизвестен, его длина неизвестна, но длина строки-то нам известна! Что в таких случаях рекомендуют классики? Дихотомию!
Вывернем задачу наизнанку:
- Ищем по началу строки текущей длины префиксы в базе префиксным поиском. 🙂
Для этого нам понадобится тот самый индекс с varchar_pattern_ops, который позволяет делать поиски по LIKE ‘anystr%’ . - Если не нашли ничего — длину префикса строки надо уменьшить в соответствии с шагом дихотомии.
- Если нашли — увеличить длину префикса.
- Если наконец получилось, что для префикса длины N форматы находятся, а для длины N+1 уже ни одного, то берем найденные для N и анализируем по первому варианту совпадающих префиксов.
>> исходная строка [1:54]: ‘block number 12345 is out of range for relation «test»‘
>> уменьшили [1:27]: ‘block number 12345 is out o’
>> уменьшили [1:13]: ‘block number ‘
‘block number ‘ и ‘block number out of range’
>> увеличили [1:20]: ‘block number 12345 i’
…
>> уменьшили [1:14]: ‘block number 1’
значит, берем вариант от [1:13] и по regexp проверяем, что подходящий — ‘block number %u is out of range for relation «%s»‘
А вот как это выглядит в виде триггера на вставку в таблицу ошибок:
CREATE OR REPLACE FUNCTION errfmt() RETURNS trigger AS $$ DECLARE repos varchar = E'^(.*) at (?:character|position) (\\d+)$'; err dicerrmsg; matches text[]; BEGIN -- отсекаем позицию IF NEW.error ~ repos THEN SELECT rm[1] , rm[2]::integer INTO NEW.error , NEW.errpos FROM regexp_matches(NEW.error, repos) rm LIMIT 1; END IF; WITH RECURSIVE orig AS ( SELECT NEW.error str ) , T AS ( SELECT 0 i , str chk , NULL::varchar pfx , ARRAY[1, length(str), length(str)] rng FROM orig UNION ALL SELECT i + 1 -- шаг #0: формируем проверяемый префикс , CASE WHEN i % 3 = 0 THEN substr((TABLE orig), 1, rng[2]) ELSE chk END -- шаг #1: находим любой из подходящих форматов , CASE WHEN i % 3 = 1 THEN ( SELECT prefix FROM dicerrmsg WHERE prefix ~>=~ chk AND prefix ~> 1, rng[2]] -- найденный префикс формата подходит в качестве префикса всей строки WHEN starts_with((TABLE orig), pfx) THEN ARRAY[length(pfx), (length(pfx) + rng[3]) >> 1, rng[3]] -- увеличиваем длину префикса ELSE ARRAY[rng[2], (rng[2] + rng[3]) >> 1, rng[3]] END ELSE rng END FROM T WHERE rng[1] < rng[2] ) -- отбираем самый последний префикс, для которого еще был формат , pre AS ( SELECT * FROM T WHERE pfx IS NOT NULL ORDER BY i DESC LIMIT 1 ) -- отбираем наиболее подходящий формат по этому префиксу SELECT Q.* INTO err FROM pre , orig , LATERAL( SELECT * FROM dicerrmsg WHERE prefix = pfx AND str ~ regexp -- фильтруем по совпадению регулярки ) Q ORDER BY length(Q.template) DESC -- выбираем по самой длинной "константной" части LIMIT 1; -- для полученного формата с помощью его regexp выделяем аргументы IF err.errmsg IS NOT NULL THEN NEW.errmsg = err.errmsg; SELECT rm INTO matches FROM regexp_matches(NEW.error, err.regexp) rm LIMIT 1; IF array_length(matches, 1) >1 OR matches[1] <> NEW.error THEN NEW.errargs = matches; END IF; NEW.error = NULL; END IF; RETURN NEW; END; $$ LANGUAGE plpgsql; CREATE TRIGGER ins BEFORE INSERT ON err FOR EACH ROW EXECUTE PROCEDURE errfmt();Давайте убедимся на примере выше, что наш основной поисковый запрос получился вовсе не «тяжелым»:

[посмотреть на explain.tensor.ru]
А когда мы все ошибки аккуратно «разложили по полочкам», можно их подходящим образом сгруппировать по форматам и наборам аргументов и показать для дальнейшей зачистки:
Алгоритмы быстрого вычисления факториала
Понятие факториала известно всем. Это функция, вычисляющая произведение последовательных натуральных чисел от 1 до N включительно: N! = 1 * 2 * 3 *… * N. Факториал — быстрорастущая функция, уже для небольших значений N значение N! имеет много значащих цифр.
Попробуем реализовать эту функцию на языке программирования. Очевидно, нам понадобиться язык, поддерживающий длинную арифметику. Я воспользуюсь C#, но с таким же успехом можно взять Java или Python.
Наивный алгоритм
Итак, простейшая реализация (назовем ее наивной) получается прямо из определения факториала:
static BigInteger FactNaive(int n)
На моей машине эта реализация работает примерно 1,6 секунд для N=50 000.
Далее рассмотрим алгоритмы, которые работают намного быстрее наивной реализации.
Алгоритм вычисления деревом
Первый алгоритм основан на том соображении, что длинные числа примерно одинаковой длины умножать эффективнее, чем длинное число умножать на короткое (как в наивной реализации). То есть нам нужно добиться, чтобы при вычислении факториала множители постоянно были примерно одинаковой длины.
Пусть нам нужно найти произведение последовательных чисел от L до R, обозначим его как P(L, R). Разделим интервал от L до R пополам и посчитаем P(L, R) как P(L, M) * P(M + 1, R), где M находится посередине между L и R, M = (L + R) / 2. Заметим, что множители будут примерно одинаковой длины. Аналогично разобьем P(L, M) и P(M + 1, R). Будем производить эту операцию, пока в каждом интервале останется не более двух множителей. Очевидно, что P(L, R) = L, если L и R равны, и P(L, R) = L * R, если L и R отличаются на единицу. Чтобы найти N! нужно посчитать P(2, N).
Посмотрим, как будет работать наш алгоритм для N=10, найдем P(2, 10):
P(2, 10)
P(2, 6) * P(7, 10)
( P(2, 4) * P(5, 6) ) * ( P(7, 8) * P(9, 10) )
( (P(2, 3) * P(4) ) * P(5, 6) ) * ( P(7, 8) * P(9, 10) )
( ( (2 * 3) * (4) ) * (5 * 6) ) * ( (7 * 8) * (9 * 10) )
( ( 6 * 4 ) * 30 ) * ( 56 * 90 )
( 24 * 30 ) * ( 5 040 )
720 * 5 040
3 628 800
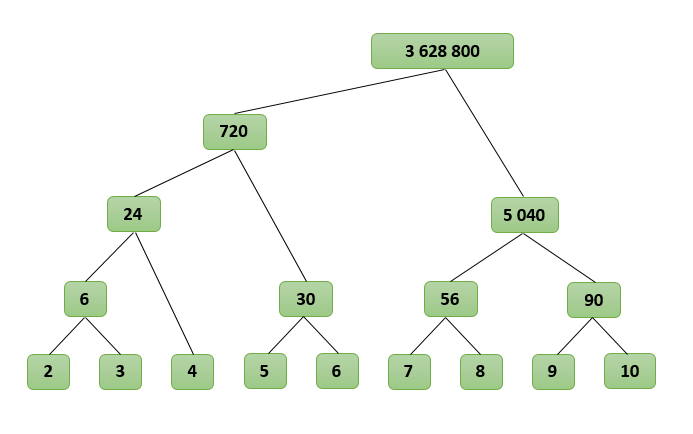
Получается своеобразное дерево, где множители находятся в узлах, а результат получается в корне
Реализуем описанный алгоритм:
static BigInteger ProdTree(int l, int r) < if (l >r) return 1; if (l == r) return l; if (r - l == 1) return (BigInteger)l * r; int m = (l + r) / 2; return ProdTree(l, m) * ProdTree(m + 1, r); > static BigInteger FactTree(int n)
Для N=50 000 факториал вычисляется за 0,9 секунд, что почти вдвое быстрее, чем в наивной реализации.
Алгоритм вычисления факторизацией
Второй алгоритм быстрого вычисления использует разложение факториала на простые множители (факторизацию). Очевидно, что в разложении N! участвуют только простые множители от 2 до N. Попробуем посчитать, сколько раз простой множитель K содержится в N!, то есть узнаем степень множителя K в разложении. Каждый K-ый член произведения 1 * 2 * 3 *… * N увеличивает показатель на единицу, то есть показатель степени будет равен N / K. Но каждый K 2 -ый член увеличивает степень еще на единицу, то есть показатель становится N / K + N / K 2 . Аналогично для K 3 , K 4 и так далее. В итоге получим, что показатель степени при простом множителе K будет равен N / K + N / K 2 + N / K 3 + N / K 4 +…
Для наглядности посчитаем, сколько раз двойка содержится в 10! Двойку дает каждый второй множитель (2, 4, 6, 8 и 10), всего таких множителей 10 / 2 = 5. Каждый четвертый дает четверку (2 2 ), всего таких множителей 10 / 4 = 2 (4 и 8). Каждый восьмой дает восьмерку (2 3 ), такой множитель всего один 10 / 8 = 1 (8). Шестнадцать (2 4 ) и более уже не дает ни один множитель, значит, подсчет можно завершать. Суммируя, получим, что показатель степени при двойке в разложении 10! на простые множители будет равен 10 / 2 + 10 / 4 + 10 / 8 = 5 + 2 + 1 = 8.
Если действовать таким же образом, можно найти показатели при 3, 5 и 7 в разложении 10!, после чего остается только вычислить значение произведения:
10! = 2 8 * 3 4 * 5 2 * 7 1 = 3 628 800
Осталось найти простые числа от 2 до N, для этого можно использовать решето Эратосфена:
static BigInteger FactFactor(int n) < if (n < 0) return 0; if (n == 0) return 1; if (n == 1 || n == 2) return n; bool[] u = new bool[n + 1]; // маркеры для решета Эратосфена List> p = new List>(); // множители и их показатели степеней for (int i = 2; i 0) < c += k; k /= i; >// запоминаем множитель и его показатель степени p.Add(new Tuple(i, c)); // просеиваем составные числа через решето int j = 2; while (i * j > // вычисляем факториал BigInteger r = 1; for (int i = p.Count() - 1; i >= 0; --i) r *= BigInteger.Pow(p[i].Item1, p[i].Item2); return r; > Эта реализация также тратит примерно 0,9 секунд на вычисление 50 000!
Библиотека GMP
Как справедливо отметил pomme скорость вычисления факториала на 98% зависит от скорости умножения. Попробуем протестировать наши алгоритмы, реализовав их на C++ с использованием библиотеки GMP. Результаты тестирования приведены ниже, по ним получается что алгоритм умножения в C# имеет довольно странную асимптотику, поэтому оптимизация дает относительно небольшой выигрыш в C# и огромный в C++ с GMP. Однако этому вопросу вероятно стоит посвятить отдельную статью.
Сравнение производительности
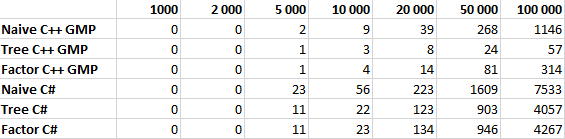
Все алгоритмы тестировались для N равном 1 000, 2 000, 5 000, 10 000, 20 000, 50 000 и 100 000 десятью итерациями. В таблице указано среднее значение времени работы в миллисекундах.
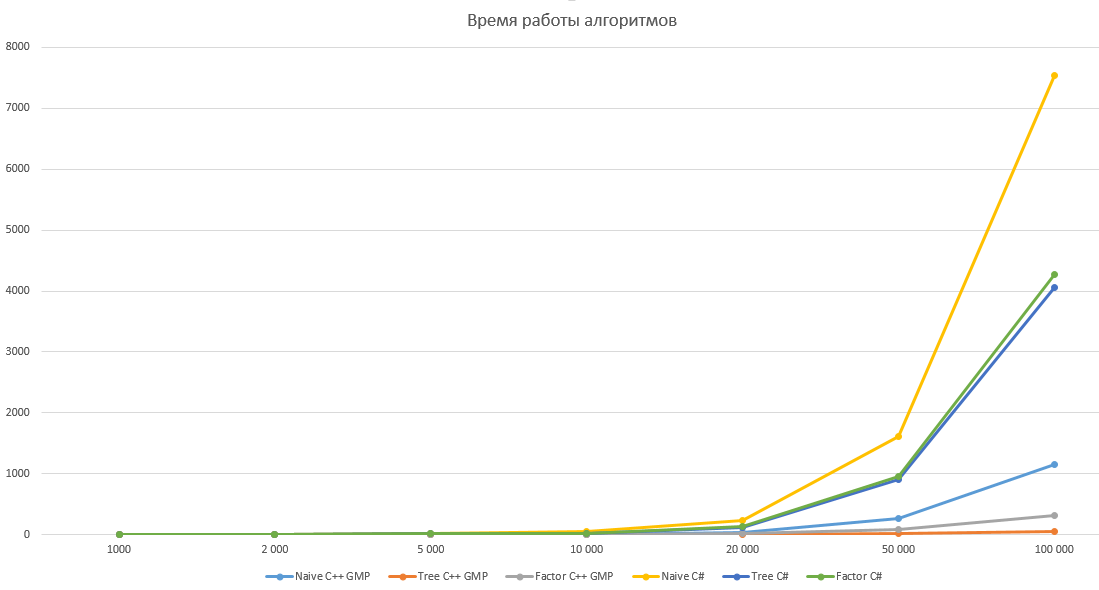
График с линейной шкалой
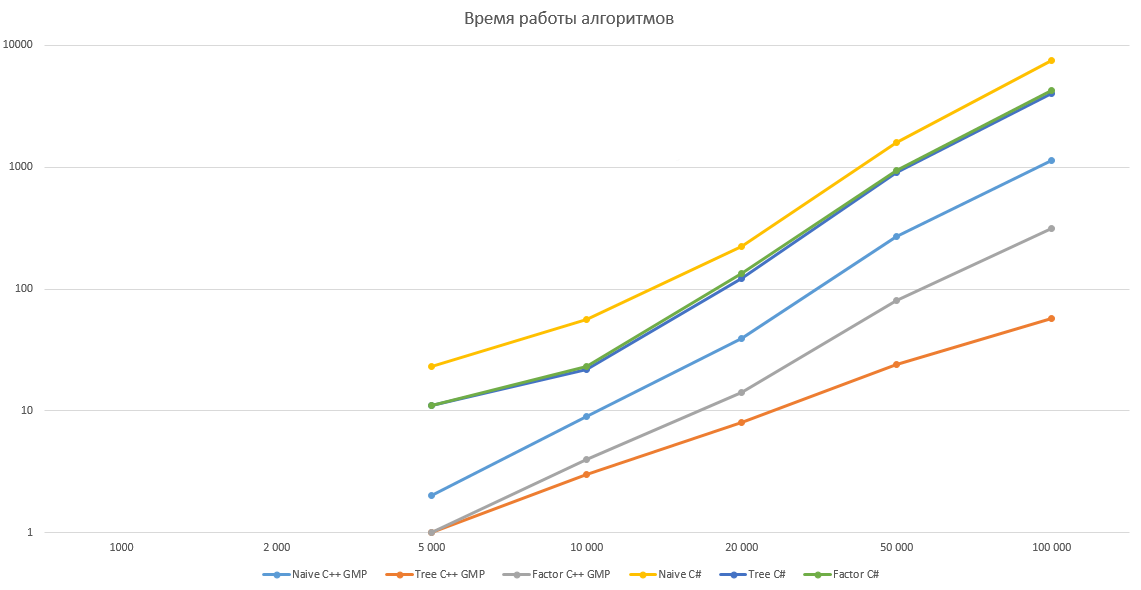
График с логарифмической шкалой
Идеи и алгоритмы из комментариев
Хабражители предложили немало интересных идей и алгоритмов в ответ на мою статью, здесь я оставлю ссылки на лучшие из них
Исходные коды
Исходные коды реализованных алгоритмов приведены под спойлерами
using System; using System.Linq; using System.Text; using System.Numerics; using System.Collections.Generic; using System.Collections.Specialized; namespace BigInt < class Program < static BigInteger FactNaive(int n) < BigInteger r = 1; for (int i = 2; i static BigInteger ProdTree(int l, int r) < if (l >r) return 1; if (l == r) return l; if (r - l == 1) return (BigInteger)l * r; int m = (l + r) / 2; return ProdTree(l, m) * ProdTree(m + 1, r); > static BigInteger FactTree(int n) < if (n < 0) return 0; if (n == 0) return 1; if (n == 1 || n == 2) return n; return ProdTree(2, n); >static BigInteger FactFactor(int n) < if (n < 0) return 0; if (n == 0) return 1; if (n == 1 || n == 2) return n; bool[] u = new bool[n + 1]; List> p = new List>(); for (int i = 2; i 0) < c += k; k /= i; >p.Add(new Tuple(i, c)); int j = 2; while (i * j > BigInteger r = 1; for (int i = p.Count() - 1; i >= 0; --i) r *= BigInteger.Pow(p[i].Item1, p[i].Item2); return r; > static void Main(string[] args) < int n; int t; Console.Write("n = "); n = Convert.ToInt32(Console.ReadLine()); t = Environment.TickCount; BigInteger fn = FactNaive(n); Console.WriteLine("Naive time: ms", Environment.TickCount - t); t = Environment.TickCount; BigInteger ft = FactTree(n); Console.WriteLine("Tree time: ms", Environment.TickCount - t); t = Environment.TickCount; BigInteger ff = FactFactor(n); Console.WriteLine("Factor time: ms", Environment.TickCount - t); Console.WriteLine("Check: ", fn == ft && ft == ff ? "ok" : "fail"); > > > C++ с GMP
#include #include #include #include #include using namespace std; mpz_class FactNaive(int n) < mpz_class r = 1; for (int i = 2; i mpz_class ProdTree(int l, int r) < if (l >r) return 1; if (l == r) return l; if (r - l == 1) return (mpz_class)r * l; int m = (l + r) / 2; return ProdTree(l, m) * ProdTree(m + 1, r); > mpz_class FactTree(int n) < if (n < 0) return 0; if (n == 0) return 1; if (n == 1 || n == 2) return n; return ProdTree(2, n); >mpz_class FactFactor(int n) < if (n < 0) return 0; if (n == 0) return 1; if (n == 1 || n == 2) return n; vectoru(n + 1, false); vector > p; for (int i = 2; i 0) < c += k; k /= i; >p.push_back(make_pair(i, c)); int j = 2; while (i * j > mpz_class r = 1; for (int i = p.size() - 1; i >= 0; --i) < mpz_class w; mpz_pow_ui(w.get_mpz_t(), mpz_class(p[i].first).get_mpz_t(), p[i].second); r *= w; >return r; > mpz_class FactNative(int n) < mpz_class r; mpz_fac_ui(r.get_mpz_t(), n); return r; >int main() < int n; unsigned int t; cout
- длинная арифметика
- факториал
- оптимизация
Обработка ошибок в Go

Хороший код должен правильно реагировать на непредвиденные обстоятельства, такие как ввод некорректных данных пользователем, разрыв сетевого подключения или отказ дисков. Обработка ошибок — это процесс обнаружения ситуаций, когда ваша программа находится в неожиданном состоянии, а также принятие мер для записи диагностической информации, которая будет полезна при последующей отладке.
В отличие от других языков программирования, где разработчикам нужно обрабатывать ошибки с помощью специального синтаксиса, ошибки в Go — это значения с типом error , возвращаемые функциями, как и любые другие значения. Для обработки ошибок в Go мы должны проверить ошибки, которые могут возвращать функции, решить, существует ли ошибка, а также принять надлежащие меры для защиты данных и сообщить пользователям или операторам, что произошла ошибка.
Создание ошибок
Прежде чем мы сможем обработать ошибку, нам нужно ее создать. Стандартная библиотека предоставляет две встроенные функции для создания ошибок: errors.New и fmt.Errorf . Обе эти функции позволяют нам указывать настраиваемое сообщение об ошибке, которое вы можете отображать вашим пользователям.
errors.New получает один аргумент — сообщение об ошибке в виде строки, которую вы можете настроить, чтобы предупредить ваших пользователей о том, что пошло не так.
Попробуйте запустить следующий пример, чтобы увидеть ошибку, созданную с помощью errors.New , которая выполняет стандартный вывод:
package main import ( "errors" "fmt" ) func main() err := errors.New("barnacles") fmt.Println("Sammy says:", err) > OutputSammy says: barnacles Мы использовали функцию errors.New из стандартной библиотеки для создания нового сообщения об ошибке со строкой "barnacles" в качестве сообщения об ошибке. Мы выполняли требование конвенции, используя строчные буквы для сообщения об ошибке, как показано в руководстве по стилю для языка программирования Go.
Наконец, мы использовали функцию fmt.Println для объединения сообщения о ошибке со строкой "Sammy says:" .
Функция fmt.Errorf позволяет динамически создавать сообщение об ошибке. Ее первый аргумент — это строка, которая содержит ваше сообщение об ошибке с заполнителями, такими как %s для строки и %d для целых чисел. fmt.Errorf интерполирует аргументы, которые находятся за этой форматированной строкой, на эти заполнители по порядку:
package main import ( "fmt" "time" ) func main() err := fmt.Errorf("error occurred at: %v", time.Now()) fmt.Println("An error happened:", err) > OutputAn error happened: Error occurred at: 2019-07-11 16:52:42.532621 -0400 EDT m=+0.000137103 Мы использовали функцию fmt.Errorf для создания сообщения об ошибке, которое будет включать текущее время. Форматированная строка, которую мы предоставили fmt.Errorf , содержит директиву форматирования %v , которая указывает fmt.Errorf использовать формат по умолчанию для первого аргумента, предоставленного после форматированной строки. Этот аргумент будет текущим временем, предоставленным функцией time.Now из стандартной библиотеки. Как и в предыдущем примере, мы добавляем в сообщение об ошибке короткий префикс и выводим результат стандартным образом, используя fmt.Println .
Обработка ошибок
Обычно вы будете видеть ошибки, создаваемые таким образом для использования сразу же без какой-либо цели, как показано в предыдущем примере. На практике гораздо чаще функция создает ошибку и возвращает ее, когда что-то происходит неправильно. Вызывающий эту функцию будет использовать оператор if , чтобы убедиться, что ошибка присутствует, или nil , неинициализированное значение.
В следующем примере содержится функция, которая всегда возвращает ошибку. Обратите внимание, что при запуске программы выводится тот же результат, что и в предыдущем примере, хотя функция на этот раз возвращает ошибку. Объявление ошибки в другом месте не изменяет сообщение об ошибке.
package main import ( "errors" "fmt" ) func boom() error return errors.New("barnacles") > func main() err := boom() if err != nil fmt.Println("An error occurred:", err) return > fmt.Println("Anchors away!") > OutputAn error occurred: barnacles Здесь мы определяем функцию под именем boom() , которая возвращает error , которую мы создаем с помощью errors.New . Затем мы вызываем эту функцию и захватываем ошибку в строке err := boom() . После получения этой ошибки мы проверяем, присутствует ли она, с помощью условия if err ! = nil . Здесь условие всегда выполняет оценку на true , поскольку мы всегда возвращаем error из boom() .
Это не всегда так, поэтому лучше использовать логику, обрабатывающую случаи, когда ошибка отсутствует ( nil ) и случаи, когда ошибка есть. Когда ошибка существует, мы используем fmt.Println для вывода ошибки вместе с префиксом, как мы делали в предыдущих примерах. Наконец, мы используем оператор return , чтобы пропустить выполнение fmt.Println("Anchors away!") , поскольку этот код следует выполнять только при отсутствии ошибок.
Примечание: конструкция if err ! = nil , показанная в последнем примере, является стандартной практикой обработки ошибок в языке программирования Go. Если функция может генерировать ошибку, важно использовать оператор if , чтобы проверить наличие ошибки. Таким образом, код Go естественным образом имеет логику "happy path"на первом уровне условия и логику "sad path"на втором уровне условия.
Операторы if имеют опциональное условие назначения, которое можно использовать для сжатия вызова функции и обработки ее ошибок.
Запустите следующую программу, чтобы увидеть те же результаты, что и в нашем предыдущем примере, но в этот раз с помощью оператора if для сокращения количества шаблонного кода:
package main import ( "errors" "fmt" ) func boom() error return errors.New("barnacles") > func main() if err := boom(); err != nil fmt.Println("An error occurred:", err) return > fmt.Println("Anchors away!") > OutputAn error occurred: barnacles Как и ранее, у нас есть функция boom() , которая всегда возвращает ошибку. Мы присвоим ошибку, возвращаемую boom() , переменной err в первой части оператора if . Эта переменная err будет доступна во второй части оператора if после точки с запятой. Мы должны убедиться в наличии ошибки и вывести нашу ошибку с коротким префиксом, как мы уже делали до этого.
В этом разделе мы научились обрабатывать функции, которые возвращают только ошибки. Подобные функции распространены широко, но также важно иметь возможность обрабатывать ошибки из функций, которые могут возвращать несколько значений.
Возврат ошибок вместе со значениями
Функции, возвращающие одно значение ошибки, часто относятся к функциям, выполняющим изменения с сохранением состояния, например, вставляющим строки в базу данных. Также вы можете написать функции, возвращающие значение при успешном завершении работы и ошибку, если работа функции завершилась сбоем. Go позволяет функциям возвращать более одного результата, т. е. они могут использоваться для возврата как значения, так и типа ошибки.
Чтобы создать функцию, которая возвращает несколько значений, мы перечислим типы всех возвращаемых значений внутри скобок в сигнатуре функции. Например, функция capitalize , которая возвращает string и error , будет объявлена следующим образом: func capitalize(name string) (string, error) <> . Часть (string, error) сообщает компилятору Go, что эта функция возвращает строку и ошибку в указанном порядке.
Запустите следующую программу, чтобы увидеть вывод функции, которая возвращает string и error :
package main import ( "errors" "fmt" "strings" ) func capitalize(name string) (string, error) if name == "" return "", errors.New("no name provided") > return strings.ToTitle(name), nil > func main() name, err := capitalize("sammy") if err != nil fmt.Println("Could not capitalize:", err) return > fmt.Println("Capitalized name:", name) > OutputCapitalized name: SAMMY Мы определяем capitalize() как функцию, которая принимает строку (имя, которое нужно указать с большой буквы) и возвращает строку и значение ошибки. В main() мы вызываем capitalize() и присваиваем два значения, возвращаемые функцией, для переменных name и err , разделив их запятой с левой стороны оператора := . После этого мы выполняем нашу проверку if err ! = nil , как показано в предыдущих примерах, используя стандартный вывод и fmt.Println , если ошибка присутствует. Если ошибок нет, мы выводим Capitalized name: SAMMY .
Попробуйте изменить строку "sammy" в name, err := capitalize("sammy") на пустую строку ("") и получите вместо этого ошибку Could not capitalize: no name provided .
Функция capitalize возвращает ошибку, когда вызов функции предоставляет пустую строку в качестве параметра name . Когда параметр name не является пустой строкой, capitalize() использует strings.ToTitle для замены строчных букв на заглавные для параметра name и возвращает nil для значения ошибки.
Существует несколько конвенций, которым следует этот пример и которые типичны для Go, но не применяются компилятором Go. Когда функция возвращает несколько значений, включая ошибку, конвенция просит, чтобы мы возвращали error последним элементом. При возвращении ошибки функцией с несколькими возвращаемыми значениями, идиоматический код Go также устанавливает для любого значения, не являющегося ошибкой, нулевое значение. Нулевое значение — это, например, пустая строка для string, 0 для целых чисел, пустая структура для структур и nil для интерфейса и типов указателя и т. д. Мы более подробно познакомимся с нулевыми значениями в нашем руководстве по переменным и константам.
Сокращение шаблонного кода
Соблюдение этих конвенций может стать трудновыполнимой задачей в ситуациях, когда существует множество значений, возвращаемых функцией. Мы можем использовать анонимную функцию для сокращения объема кода. Анонимные функции — это процедуры для переменных. В отличие от функций, описанных в предыдущих примерах, они доступны только в функциях, где вы их объявили, что делает их идеальным инструментом для использования в коротких элементах вспомогательной логики.
Следующая программа изменяет последний пример, чтобы включить длину имени, которое мы будем переводить в верхний регистр. Поскольку функция возвращает три значения, обработка ошибок может стать громоздкой без анонимной функции, которая может нам помочь:
package main import ( "errors" "fmt" "strings" ) func capitalize(name string) (string, int, error) handle := func(err error) (string, int, error) return "", 0, err > if name == "" return handle(errors.New("no name provided")) > return strings.ToTitle(name), len(name), nil > func main() name, size, err := capitalize("sammy") if err != nil fmt.Println("An error occurred:", err) > fmt.Printf("Capitalized name: %s, length: %d", name, size) > OutputCapitalized name: SAMMY, length: 5 Внутри main() мы получим три возвращаемых аргумента из capitalize : name , size и err . Затем мы проверим, возвращает ли capitalize error , убедившись, что переменная err не равна nil . Это важно сделать, прежде чем пытаться использовать любое другое значение, возвращаемое capitalize , поскольку анонимная функция handle может задать для них нулевые значения. Поскольку ошибок не возникает, потому что мы предоставили строку "sammy" , мы выведем состоящее из заглавных букв имя и его длину.
Вы снова можете попробовать заменить "sammy" на пустую строку ("") и увидеть ошибку ( An error occurred: no name provided ).
Внутри capitalize мы определяем переменную handle как анонимную функцию. Она получает одну ошибку и возвращает идентичные значения в том же порядке, что и значения, возвращаемые capitalize . handle задает для них нулевые значения и перенаправляет error , переданную в качестве аргумента, как конечное возвращаемое значение. Таким образом мы можем вернуть любые ошибки, возникающие в capitalize , с помощью оператора return перед вызовом handle с error в качестве параметра.
Помните, что capitalize должна возвращать три значения всегда, поскольку так мы установили при определении функции. Иногда мы не хотим работать со всеми значениями, которые функция может возвращать. К счастью, у нас есть определенная гибкость в отношении того, как мы можем использовать эти значения на стороне назначения.
Обработка ошибок функций с несколькими возвращаемыми значениями
Когда функция возвращает множество значений, Go требует, чтобы каждое из них было привязано к переменной. В последнем примере мы делали это, указав имена двух значений, возвращаемых функцией capitalize . Эти имена должны быть разделены запятыми и отображаться слева от оператора := . Первое значение, возвращаемое capitalize , будет присвоено переменной name , а второе значение ( error ) будет присваиваться переменной err . Бывает, что нас интересует только значение ошибки. Вы можете пропустить любые нежелательные значения, которые возвращает функция, с помощью специального имени переменной _ .
В следующей программе мы изменили наш первый пример с функцией capitalize для получения ошибки, передав функции пустую строку ("") . Попробуйте запустить эту программу, чтобы увидеть, как мы можем изучить только ошибку, убрав первое возвращаемое значение с переменной _ :
package main import ( "errors" "fmt" "strings" ) func capitalize(name string) (string, error) if name == "" return "", errors.New("no name provided") > return strings.ToTitle(name), nil > func main() _, err := capitalize("") if err != nil fmt.Println("Could not capitalize:", err) return > fmt.Println("Success!") > OutputCould not capitalize: no name provided Внутри функции main() на этот раз мы присвоим состоящее из заглавных букв имя ( строка , возвращаемая первой) переменной с нижним подчеркиванием ( _ ). В то же самое время мы присваиваем error , которую возвращает capitalize , переменной err . Теперь мы проверим, существует ли ошибка в if err ! = nil. Поскольку мы жестко задали пустую строку как аргумент для capitalize в строке _, err := capitalize("") , это условие всегда будет равно true . В результате мы получим вывод "Could not capitalize: no name provided" при вызове функции fmt.Println в теле условия if . Оператор return после этого будет пропускать fmt.Println("Success!") .
Заключение
Мы познакомились с многочисленными способами создания ошибок с помощью стандартной библиотеки и узнали, как создавать функции, возвращающие ошибки идиоматическим способом. В этом обучающем руководстве мы успешно создали различные ошибки, используя функции errors.New и fmt.Errorf стандартной библиотеки. В будущих руководствах мы рассмотрим, как создавать собственные типы ошибок для предоставления более полной информации пользователям.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
Глоссарий маркетинга в социальных медиа

Бриф ― это документ, где заказчик развивает свои фантазийные способности, а исполнителю потом приходится все расхлебывать.
В
Вводные сообщения (автоматические ответы) ― это список часто задаваемых вопросов в Direct Instaram, при нажатии на которые, пользователь сразу получает ответ. Настроить их можно в LiveDune.

Взаимопиар ― метод обмена аудиториями между двумя аккаунтами. Например, взаимная рекомендация другого аккаунта в stories. Взаимопиар и другие методы бесплатного продвижения в статье.
Виральность — особенность контента, которая определяет вероятность желания читателей поделиться этим контентом.
Виральный охват (вирусный) — это число пользователей, не подписанных на аккаунт/сообщество, которые увидели пост/аккаунт благодаря чужому репосту, отметке или упоминанию. То есть охваты, за которые вы не платили.
Вовлеченность (Engagement Rate / ER) ― это процент активной аудитории аккаунта. Под активностью подразумеваются различные реакции пользователей на публикации (лайки, комментарии, сохранения, голоса, репосты и т.д.).

Узнать ER своего аккаунта и сравнить с конкурентами 7 дней бесплатно
Формула: ER = (ср. кол-во реакций на пост / кол-во подписчиков) * 100%
Например, за выбранный период было опубликовано 10 постов, которые набрали 100 лайков и 20 комментариев. В среднем получится (100 + 20) / 10 = 12 взаимодействий на пост. В аккаунте 300 подписчиков, соответственно, ER = 12 / 300 * 100 = 4%.
Г
Геймификация — использование игровых механик в соцсетях для увеличения вовлеченности аудитории. Варианты игр в постах и stories можно посмотреть в статье.
Д
Дедлайн ― день прощания. День, когда горят костры рябин. Как костры горят обещанья. В день, когда ты с задачей один на один.
Душнила – клиент, который шлет по 500 000 правок.
К
Контент-план ― это график планируемых тем для публикации в аккаунте/сообществе. Как составить контент-план описали здесь + шаблон.
Контент-срам ― график планируемых публикаций, который составлен без анализа интересов пользователей.
Кросспостинг — это дублирование одного материала в разные соцсети.
Курирование контента ― это повторное использование своего/чужого контента с частичной переработкой. Например, тезисное изложение чужого материала, краткий вывод по исследованию, комментирование и т.д. Подробнее в статье.
Л
Лиды (Leads) ― это конкретные действия пользователей, которые отбираются по нужным критериям (например, заполненная заявка).
М
Масслайкинг — это массовое проставление лайков к контенту пользователей соцсетей. Считается серой механикой продвижения из-за чего аккаунт может быть заблокирован.
Массфоловинг — это массовое добавление пользователей в друзья/подписчики. Наряду с масслайкингом ― является серой механикой продвижения.
Медиаплан — это подробный документ, регламентирующий сроки проведения рекламной кампании, используемые каналы, основные настройки и бюджет.
Мультиссылка ― это мини-лендинг, который служит для размещения краткой информации о вас, контактов и ссылок на несколько ресурсов. Обычно используется в Instagram, так как в шапке профиля нельзя добавить несколько ссылок. Подробнее в статье.
Н
Накрутка — искусственное увеличение ключевых параметров сообществ или аккаунтов в соцсетях: подписчики, лайки, комментарии.
О
Оценки постов ― это распределение постов от лучших к худшим на основе скорости набора лайков. Внутренняя метрика LiveDune. Этот показатель помогает объективно оценить качество своего и конкурентного контента в Instagram. Подробнее.
Охват (Reach) — это количество уникальных пользователей, просмотревших пост, stories, рекламное объявление или аккаунт. Например, подписчик посмотрел пост 3 раза, значит будет 1 охват и 3 просмотра. Подробнее.
П
Просмотры (Views) — это суммарное количество просмотров вашего поста/stories/аккаунта/рекламного объявления. То есть если один пользователь открывал ваш пост 5 раз, то в просмотры засчитается +5, а в охват +1. Просмотры всегда больше, чем охват.
Путеводители Инстаграм ― формат контента в Instagram, который представляет собой подборку разных публикаций товаров или мест. Размещаются в отдельном разделе Instagram. Как сделать путеводители описали в статье.
Р
Реакции (Взаимодействия / Интеракции / Активности) — основные действия пользователей с контентом, такие как лайки, комментарии, репосты, голоса в опросах, сохранения.
Рубрики постов ― это разделение публикаций в соцсетях по тематикам. Помогают оценить эффективность тем, которые публикуются, найти непопулярные тематики среди аудитории аккаунта и отказаться от них.
Проанализировать эффективность рубрик и скорректировать контент-план 7 дней бесплатно
С
Ситуативный маркетинг — использование актуального инфоповода для увеличения охватов, повышения узнаваемости или продвижения своих услуг за счет обсуждаемого события или новости. Примеры использования.
Сторителлинг — это донесение информации через истории. Считается эффективным маркетинговым инструментом, благодаря которому можно мотивировать человека на определенные действия. Подробнее описали в статье.
CMM-нытик ― специалист, который всегда драматизирует и считает, что все поставленные KPI невыполнимы.
А
Ads Manager ― это рекламный кабинет в Facebook. В нем настраивают, запускают, корректируют и оценивают результат по рекламным кампаниям в Facebook и Instagram.
AGR (Audience Growth Rate) ― это темп роста аудитории аккаунта. Формула: AGR = ((новые подписчики – число отписавшихся) / общее количество подписчиков) * 100 %. Нормальный отток аудитории должен быть в 2-3 раза ниже, чем приток новой.
AIDA (Attention, Interest, Desire, Action) — модель потребительского поведения: внимание → интерес → желание → действие.
API (Application Programing Interface) — переводится как «Программный интерфейс приложения». Это описание способов, по которым одна программа может взаимодействовать с другой. Используется, в том числе для разработки приложений в соцсетях, упрощая программистам задачу за счет предоставления различных элементов готового кода.
B
Business Manager (Бизнес-менеджер) ― это инструмент Facebook, с помощью которого можно управлять страницами в Facebook и Instagram, рекламными кабинетами, доступами сотрудников и др.
BDSMM ― когда получаешь особое удовольствие от продвижения в соцсетях и зашел слишком далеко.
C
CPA (Cost Per Action) — стоимость целевого действия, например, заполнение формы.
Формула для расчета: CPA = расходы на РК / кол-во целевых действий
CPC (Cost Per Click) — оплата за клик по рекламному объявлению.
Формула: CPC = расходы на РК / количество кликов
CPF (Cost Per Follower) ― стоимость привлечения одного подписчика.
Формула: CPF = затраты на привлечение / количество новых подписчиков
CPL (Cost Per Lead) ― цена за лид. Метрика показывает, сколько рекламодатель платит за привлечение одного лида. Формула: CPL = расходы на РК / количество лидов с рекламы
CPM (Сost Per Mile) — стоимость за 1000 показов. Формула: CPM = расходы на РК / кол-во просмотров * 1000 показов
CR (Conversion Rate) ― конверсия в какое-то действие. Формула: CR = кол-во конверсий / кол-во посетителей × 100%
E
ER (Engagement Rate) ― это процент вовлеченной/активной аудитории аккаунта. Под активностью подразумеваются различные реакции пользователей на публикации (лайки, комментарии, сохранения, голоса, репосты и т.д.). Формула: ER = (ср. кол-во реакций на пост / кол-во подписчиков) * 100%
Например, за выбранный период было опубликовано 10 постов, которые набрали 100 лайков и 20 комментариев. В среднем получится (100 + 20) / 10 = 12 взаимодействий на пост. В аккаунте 300 подписчиков, соответственно, ER = 12 / 300 * 100 = 4%.
ERR (Engagement Rate Reach) — коэффициент вовлеченности по охвату. Метрика помогает оценить количество подписчиков, которые видели публикацию и прореагировали на нее. Формула: ERR = (ср.кол-во реакций на пост / охват) * 100
ERV (Engagement Rate Views) — показатель вовлеченности по просмотрам. Формула: ERV = (кол-во реакции / кол-во просмотров постов) * 100